« Movable Type の OpenAPI スキーマ対応をご存知ですか? | メインページ
2023年12月 1日
ブログ記事を聴こう
こんにちは。こちらは Movable Type Advent Calendar 2023 向けの記事です。
2023年のトップバッターをいただきましてありがとうございます!
改めまして、こんにちは。重田です。シックス・アパートでエンジニアをしています。
今回は「ブログ記事を読む」のではなく「ブログ記事を聴く」ことにチャレンジします。
聴く?
ブログ記事を聴くというとやはりポッドキャストが真っ先に頭に浮かびますよね。しかしポッドキャストだと mp3 など音声ファイルを別途用意する必要があります。音声ファイルを準備するにはツールやウェブサービスに頼る必要がありますし、作成した音声ファイルをホスティングする必要もあり、ポッドキャストを導入するには少し手間がかかります。
Chrome、Edge、Firefox など主要ブラウザにはウェブ音声 API (Web Speech API)が搭載されているので、JavaScript を使ってテキストを読み上げることができます。
今回は Web Speech API を使ってブラウザにブログ記事を朗読してもらいます。読者である私たちはブログ記事を聴くことができるというわけです。
Web Speech API
Web Speech API は MDN の解説に詳しく書いてあります。
Web Speech API は大きく2つに分かれます。一つは音声認識、もう一つは音声合成です。この記事では音声合成を使います。(音声認識は触れません。)
では音声合成の代表的な2つのインターフェースを把握しておきましょう。
SpeechSynthesis インターフェース
音声合成は SpeechSynthesis インターフェースを使います。
プロパティ
プロパティは次の3つです。
- paused
- pending
- speaking
これらのプロパティで SpeechSynthesis インターフェースの状態がわかります。paused は一時停止中かどうか、pending はキューに溜まっている音声があるかどうか、speaking は現在再生中かどうか、を判定できます。
paused と speaking はイメージできると思いますが、pending のキューについて「どういうこと?」と思った方もいらっしゃると思います。SpeechSynthesis インターフェースはキューになっていますので、音声をどんどん追加していくことが可能なのです。しかしながら、このキューに触れるインターフェースがないので、追加した後に操作することができませんし、何個追加されているかも知ることはできません。代わりに pending プロパティでキューに何かある、ということを知ることができます。
メソッド
主に利用するのは次のメソッドだと思います。
- getVoices
- speak
- pause
- resume
- cancel
getVoices メソッドはブラウザが持っている音声を配列で返します。SpeechSynthesisVoice オブジェクトの配列になっています。言語ごとに複数の音声があるので必要な音声を getVoices メソッド経由で入手します。
speak メソッドは再生に利用します。pause メソッドは再生中の音声を一時停止し、resume メソッドで一時停止を解除します。cancel メソッドで再生の終了をします。
SpeechSynthesisUtterance インターフェース
SpeechSynthesisUtterance は再生したい文字列を格納します。
コンストラクタ
引数に再生したい文字列を渡します。再生したい文字列を渡すのに text プロパティを使うこともできます。
プロパティ
主に利用するのは次のプロパティでしょうか。
- voice
- rate
- pitch
voide プロパティは音声を設定します。音声は SpeechSynthesis インターフェースの getVoices メソッドで取得します。再生したい言語にあった音声を voice プロパティに設定します。
rate プロパティは再生速度を指定します。デフォルトは1が設定されています。min が 0.1 で max が 10 です。2が2倍速らしいので最大10倍速までいけます。
pitch プロパティは音の高低です。デフォルトは1が設定されています。min が 0 で max が 2 です。
イベント
イベントは SpeechSynthesis インターフェースのメソッドと関連しています。start は再生時、pause は一時停止時、resume は一時停止を解除したとき、end は終了時、error はエラー時に発火します。次の例は終了時にコンソールに end と残す方法です。
ut = new SpeechSynthesisUtterance("Hello world");
ut.onend = function(ev) {
console.log("end");
};
以上、SpeechSynthesis と SpeechSynthesisUtterance を理解していれば十分です。
実装
では Developer Tools の console でも実行できる実装をみてみましょう。
window オブジェクトに speechSynthesis オブジェクトがぶら下がっているのでこれを使います。
window.speechSynthesis.speak(new SpeechSynthesisUtterance("Hello world"))
speak メソッドの引数に SpeechSynthesisUtterance のインスタンスを渡します。SpeechSynthesisUtterance のコンストラクタの引数には喋らせたい文字列を渡します。
次のように日本語を入れたら喋らない場合があります。
window.speechSynthesis.speak(new SpeechSynthesisUtterance("こんにちは"))
これは SpeechSynthesisUtterance の voice プロパティに日本語対応した声を当てれば解決します。
ut = new SpeechSynthesisUtterance("こんにちは"); // 喋る内容を定義
voices = window.speechSynthesis.getVoices(); // 声のリストを取得
for (v of voices) { if (v.lang.match(/^ja/i)) { ut.voice = v; break; } } // 日本語の声を検索
window.speechSynthesis.speak(ut); // 喋る!
利用可能な声は SpeechSynthesis の getVoices メソッドで取得できます。getVoices メソッドは SpeechSynthesisVoice オブジェクトの配列が返ってきます。SpeechSynthesisVoice には lang プロパティがあり、BCP 47 形式( 例: ja-JP )で値が格納されているので、それで調べるのがよさげです。
といった感じで文字列を聴く(音声を再生する)ことができます。簡単ですね。
Movable Type に組み込む
ブログ記事に音声プレイヤーを埋め込んでみましょう。
テンプレート
音声プレイヤー用に新しくテンプレートモジュールを用意して、記事アーカイブテンプレートに追記します。
テンプレートモジュール
次のような内容で SpeechPlayer テンプレートモジュールを用意します。
<style>
#speech-player {
right: 15px;
bottom: 15px;
padding: 20px;
position: fixed;
text-align: right;
border: 1px solid #000;
border-radius: 20px;
background-color: rgba(240, 255, 255, 0.2);
}
#speech-player button {
padding: 7px;
margin: 0px 5px 0px 5px;
}
</style>
<div id="speech-player">
<form>
<p><mt:BlogLanguage> で話します。</p>
<button id="speech" type="submit">Speech</button>
<button id="pause" type="button" disabled>Pause</button>
<button id="resume" type="button" disabled>Resume</button>
<button id="stop" type="button" disabled>Stop</button>
<fieldset>
<input type="radio" name="rate" id="rateSlow" value="0.7"><label for="rateSlow">ゆっくり</label>
<input type="radio" name="rate" id="rateMedium" value="0.9" checked><label for="rateMedium">普通</label>
<input type="radio" name="rate" id="rateFast" value="1.1"><label for="rateFast">速く</label>
<input type="radio" name="rate" id="rateAnimal" value="2.0"><label for="rateAnimal">どうぶつ</label>
</fieldset>
</form>
</div>
<script>
const synthesis = window.speechSynthesis;
document.querySelector("#pause").onclick = function(ev) {
synthesis.pause();
document.querySelector("#pause").disabled = true;
document.querySelector("#resume").disabled = false;
document.querySelector("#stop").disabled = true;
};
document.querySelector("#resume").onclick = function(ev) {
synthesis.resume();
document.querySelector("#pause").disabled = false;
document.querySelector("#resume").disabled = true;
document.querySelector("#stop").disabled = false;
};
document.querySelector("#stop").onclick = function(ev) {
synthesis.cancel();
document.querySelector("#speech").disabled = false;
document.querySelector("#pause").disabled = true;
document.querySelector("#resume").disabled = true;
document.querySelector("#stop").disabled = true;
document.querySelectorAll('input[name="rate"]').forEach(function(el) {
el.disabled = false;
});
};
document.querySelector("#speech-player form").onsubmit = function(ev) {
ev.preventDefault();
if (synthesis.speaking || synthesis.paused || synthesis.pending) {
alert("ほかで再生中なので再生できません。");
return;
}
const blogLanguage = "<mt:BlogLanguage>";
const regex = new RegExp("^" + blogLanguage, "i");
synthesis.getVoices().forEach(function(voice) {
if (voice.lang.match(regex)) {
synthesis.voice = voice;
}
});
const text = document.querySelector('.entry-asset').textContent;
const utterance = new SpeechSynthesisUtterance(text);
utterance.rate = document.querySelector('input[name="rate"]:checked').value;
utterance.onend = function(ev) {
document.querySelector("#speech").disabled = false;
document.querySelector("#pause").disabled = true;
document.querySelector("#resume").disabled = true;
document.querySelector("#stop").disabled = true;
document.querySelectorAll('input[name="rate"]').forEach(function(el) {
el.disabled = false;
});
};
utterance.onerror = function (ev) {
console.log(ev.constructor.name + ":" + ev.error);
};
utterance.lang = blogLanguage;
synthesis.speak(utterance);
document.querySelector("#speech").disabled = true;
document.querySelector("#pause").disabled = false;
document.querySelector("#stop").disabled = false;
document.querySelectorAll('input[name="rate"]').forEach(function(el) {
el.disabled = true;
});
}
</script>
記事アーカイブテンプレート
上で作成した SpeechPlayer テンプレートモジュールを の前に埋め込みます。次のように body タグを閉じる直前に入れます。
<$mt:Include module="SpeechPlayer"$>
</body>
確認
次のスクリーンショットのようにページの右下にプレイヤーが表示されます。Speech ボタンで再生します。再生中は Pause ボタンと Stop ボタンが有効になります。Pause ボタンを押すと Resume ボタンが有効になります。最後まで再生すると Speech ボタンが再度有効になります。
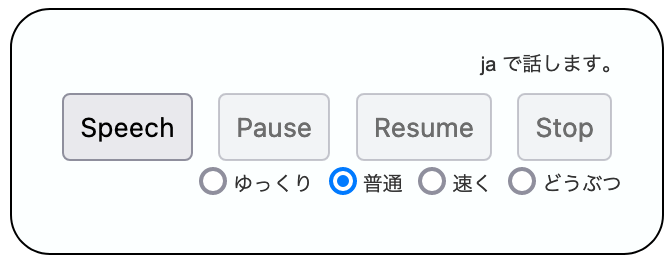
前述の通り SpeechSynthesis は SpeechSynthesisUtterance をキューするので、Speech ボタンを連打すると押した回数だけ記事の再生を繰り返してしまうので、一度だけ再生するように再生後は Speech ボタンを無効化しています。
SpeechSynthesisUtterance の rate プロパティに速度を設定するようにしました。ゆっくりは 0.7、普通は 0.9、速くは 1.1、どうぶつは 2 を設定しています。「どうぶつ」というは人気の森のゲームみたいな喋り方です。
さらにハックする
この記事で実装はしませんが、前述の例から次のアイデアが考えられます。
声の選択
Movable Type のテンプレートでは MTBlogLanguage を使って自動的に音声を選択しました。Mac Firefox の場合、かつブログの言語設定が日本語(ja)を使っている場合は SpeechSynthesis の ja-JP を使う音声は1つ(Kyoko)だけでしたので特に問題ありません。しかし、Chrome では4つ(Hattori、Kyoko、O-Ren、Google 日本語)ありました。en-US はもっとたくさんの音声があり、自動的に選ぶよりはどれかを選択したい読者もいることでしょう。そこで音声を選択できるように対応したら汎用性が上がると思います。SpeechSynthesis インターフェースの getVoices メソッドで音声を列挙できますので言語選択フォームを追加してあげるとよいでしょう。以下のような感じで言語に合ったリストを確認できます。
window.speechSynthesis.getVoices().forEach((v) => { if (v.lang.match(/^ja/i)) { console.log(v.name) } })
範囲を選択した再生
今回の例ではブログ記事全体を textContent で抽出しているので問答無用で全体を再生していますが、特にコードのところは何を言っているのか意味不明な印象もあったでしょう。pre タグは飛ばすとか範囲選択された部分のみを再生するとかそういった機能があるとより聴きやすくなると思います。textContent ではなく読みやすさを重視して記事内容をフィルタリングしてから SynthesisUtterance を用意すると音声再生を利用する読者も増えるかもしれませんね。
まとめ
今回はブラウザのウェブ音声 API の音声合成を使ってブログ記事を聴くことについて取り上げました。自然な喋り方ではないので違和感があるかもしれませんが、逆にこのくらいでも十分と感じる方もいらっしゃると思います。今回の記事で何か実装のヒントになれば幸いです。
Happy coding!
(2023/12/01 14:24 追記)
Mac の Frefox と Safari では「どうぶつ」を選んだときに何を言っているかわからない、まさにどうぶつの人気シリーズの森のキャラクターみたいな声だったんですが、Chrome だと割とちゃんと聴こえてしまうというオチにならない結果があることを教えていただきました。ぜひ Firefox や Safari でお楽しみください!
加えて、ブラウザごとに挙動に違いがある点に注意して使いたい API ですね。